A #nicar12 walkthrough -- HTML tags from 10,000 feet
Published 2012-02-24
Many things go into making a webpage pop up in a browser when you type in an URL or click a bookmark. And many things comprise that page — metadata, styles, scripts and markup — to make it do all kinds of neat and interesting things.
But when it comes time to scrape content from a webpage, it’s the markup we’re interested in. In the case of this blog post, we’re looking at HTML and a couple basic tags — or elements — that give structure to a webpage.
For the purposes of this walkthrough, an element is a section of the webpage set off by HTML tag.
HTML tags always exist in pairs. One tag — the opening tag — tells your browser that a new section of the webpage is beginning, and it will have to decide how to display it. The second tag — the closing tag — tells the browser it’s closing that element.
There are many different types of tags, and each is charged with displaying content if different ways.
We’ll start with <div>’s and <table>’s, the latter of which dominated the early days of the World Wide Web, and now are largely used only when the need arises to hold fielded data.
And when we learn to identify these basic containers and how they fit together, we begin learning how we can access the content they hold and pull off a basic scrape of content from a webpage.
Learning to identify how basic containers fit together
In many respects, us journalist-types are tailor-made to learn how a webpage. We’ve all read through a city budget line-by-line, or asked questions to learn definitions to jargon. Learning HTML tags is no different.
Remember, when you started out as a reporter? You likely didn’t know how to call about a particular issue, and the sources on the beat. You accumulated experience and knowledge, and along the way found tools.
When it comes to what we’re about to learn, there is a tool that is indispensible… Web Inspector
I’ll give you some basics to web inspector, or you can Google “web inspector”, or find Dan Nguyen’s tip sheet from NICAR12.
The easiest method is to — hopefully using the latest version of Firefox, Chrome or Safari — highlight something on a webpage, right-click on it and select “Inspect Element.”
So we’ll go to a page that lists Abbotsford child day care facilities and right-click on any element on the page. Doing so will bring up a console with all kinds of code and options and tabs that can look all kinds of scary at first.
To begin, we’re concerned with the main window, which contains the code that creates the webpage you are looking at.
Let’s all get on the same page by selection the first link on the page — A-Zee’s Childcare — selecting it and right-clicking.
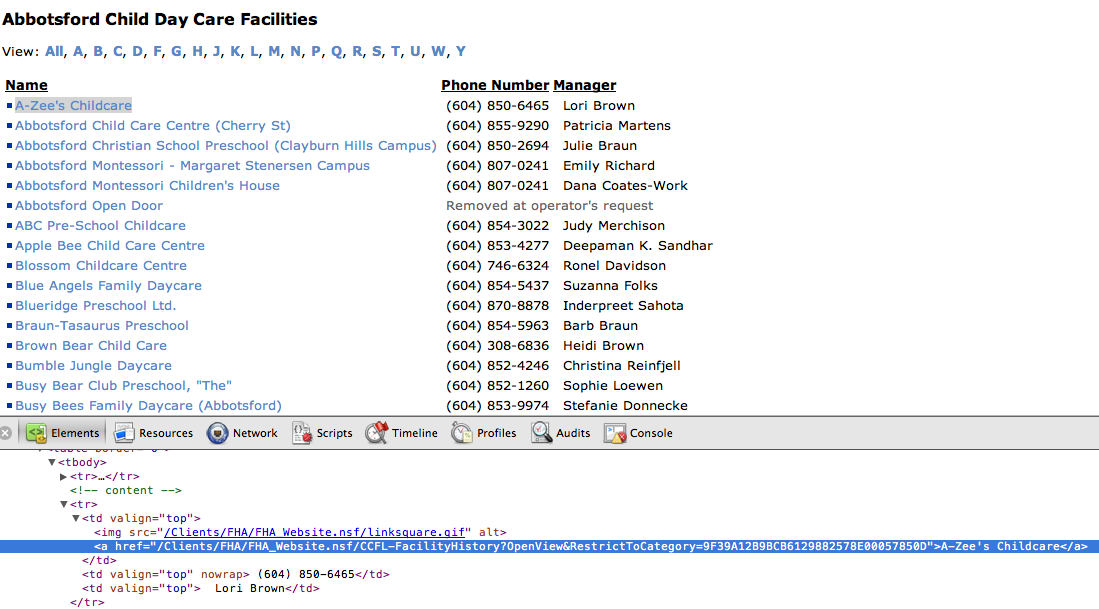
You will see that A-Zee’s Childcare is contained within an anchor tag, the kind of HTML that allows the World Wide Web to function by linking pages together.
Often when trying to scrape webpages, the thing we highlight and inspect is the content we want, but our efforts can best be served by working our way out to larger content containers. So as we move out farther, this is what we see:
<tr>
<td valign="top">
<img src="/Clients/FHA/FHA_Website.nsf/linksquare.gif" alt="">
A-Zee's Childcare
</td>
<td valign="top" nowrap=""> (604) 850-6465</td>
<td valign="top"> Lori Brown</td>
</tr>And as we’re about to learn, when we see <tr> and <td> on a webpage we can be sure that a <table> is close by.
<table>’s
If you are familiar with a spreadsheet — a series of columns and rows and cells — that’s basically all a HTML table is. And using tags it delivers a series of rows and cells to a webpage making it really easy to spot on a page. When looking for content that I want to scrape or pull into a spreadsheet, if I see a table, I begin to salivate.
First of all, and HTML table looks like a spreadsheet. It has rows that are created from top to bottom, and cells that are created from left to right.
It begins with the <table> tag, which really is nothing more than a container to house the rows and cells.
Within the <table> tag, rows begin with a <tr> tag and end with </tr>.
Within the row — <tr></tr> —you’ll find the cells that hold content. These begin with a tag and end with .
Here’s a sample table:
<table>
<tr>
<td>First Row, First Cell</td>
<td>First Row, Second Cell</td>
</tr>
<tr>
<td>Second Row, First Cell</td>
<td>Second Row, Second Cell</td>
</tr>
</table>Each of these tags could have their own attributes, or instructions for the web browser that tell it a certain way to act when it encounters one.
For instance you might see:
<table id="firsttable">
which indicates — because IDs are unique to a tag — that it’s a unique instance of <table>. When it comes to scraping, I like IDs because it allows me to target it exactly.
You might also see a class. A class in HTML is a more general attribute, one that can be used over and over, and on different kinds of tags.
Whereas an ID should only appear once, a class may appear over and over again. So on a web page, you might see:
<table class="purple"> <table class="description"> <table class="author_bio">
IDs and classes aren’t unique to <table>’s. In fact that can be applied to any HTML tag.
<div class="description"> <ul id="author_bio"> <p class="author_bio" href="http://mysite.com">
To repeat, any webpage worth its design will have one instance of a particular ID, but it can be several instances of a class.
<ul> and <p> tags are also HTML elements, and can be targeted for a scrape, but generally are some of the smaller elements you will target.
But the <div>. That’s a good one.
Wonderfully general piece of advice: When learning to scrape, it’s nice to start big and whittle down.
<div>’s
When I started to learn HTML <div>’s were hard for me to understand. I can’t remember exactly what made the concept click.
My gut tells me it took practice, practice and more practice to finally understand how these tags fit together and how they can be manipulated.
Think about it in terms of learning to play the guitar. You learn two or three chords, strum a bit, make little ditties, repeat.
And I like to think of
<div>’s are the ultimate multi-purpose container, and can be used to hold tables, lists, paragraphs — OK anything — on a webpage. And by targeting their IDs and classes, we can drill down and capture the content.
lists
On a webpage, lists come in a couple varieties: unordered — designated by a <ul> tag — and ordered — designated by a <ol> tag. Both contain a series of items that are contained in <li> tags or “list item” tags.
In my experience the most common variety is the unordered kind.
Like all HTML elements, you can assign IDs and classes to list items — both <ul> tags and <li> tags, which allows us to select them when inspecting a page we want to scrape.